Enable independent E2E test with version routing
By leveraging Service Mesh and Distributed Tracing in our microservice infrastructure, we have enabled the testing environment with multiple versions of the system running in parallel, isolated, and reliable.

1. Overview
We all know how necessary testing is, it is a must, but are we doing it effectively? I believe that testing, as one of the fundamental parts of software development, should be done easily and reliably as possible.
Why easily? I am not talking about how easily your tests could be passed, but my point is how effortless everyone (dev guys, QC guys,) needs to perform on setting up to do a test. That point is one of the key aspects that many people miss because if the test is too hard to set up, you would likely ignore it, or find some way to work around it. For example: if the test takes hours to set up, which mostly includes the effort to align among stakeholders, do we want to do it daily? Likely not, we will suspend the test effort until the very last days of the development cycle, we postpone it because it is expensive, and the later we test, the later the bugs are found.
Reliability is another aspect that your test should be guaranteed. The more reliable the test is, the more chance we have to detect real issues, and the less time we have to spend investigating some randomness caused by the chaos of the testing environment. We know how it feels to spend hours debugging on a sandbox environment and then find out a bug that is completely not related to our work, these burdens can burn you out quickly.
Unfortunately, the higher level our test goes, the harder it takes to guarantee both effortlessness and reliability in your tests. When it comes to end-to-end tests, which involve many counterparts working in parallel to synchronize their works during the test, the effort spent on orchestrating resources: human, deployments could be irritating.
So, what kind of tests are we talking about?
End-to-end testing aims at testing our product as a whole system, the flow should run from beginning to the end to make all involved subsystems or services actually execute to fulfill a flow. It helps to cover the integrations and dependencies among components in our system to work together as expected.
The E2E tests simulate real-life scenarios closely, so it is much more complex and gives us the highest confidence in our product to make sure that our product actually works. [1] [2]
2. How do we develop the system at ZaloPay?
At ZaloPay, we apply microservices architecture, which "enables each service to be developed independently by a team that is focused on that service" [3]. The concept sounds appealing. However, a team cannot get complete freedom in testing as much as they have in implementation, especially in E2E tests. In fact, microservices add more complexity to this process.
2.1. Development Process
Now, let's take a closer look at how we develop our services by examining an example. To fulfill a request for a user, a chain of requests must be served by service A, service B, and then service C, which reflects the dependency among services in our system.

What happens if we want to develop a new feature which needs the involvement of Service B and Service C? The implementation will be done independently, and the time has come for an end-to-end test when each team deploys their service in a sandbox environment and asks for their QC guys to come by and take a look.
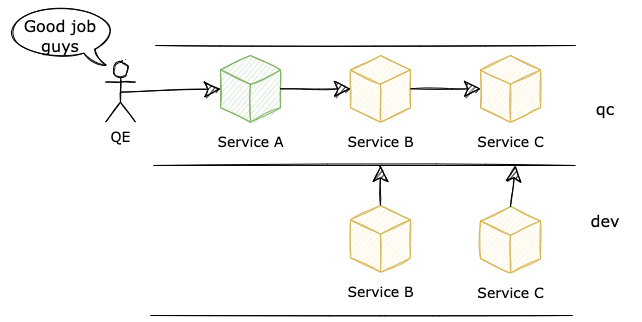
2.2. Challenges
However, one team is not in charge of only one feature at a time, there may be many features in development in parallel. What happens if team B has another feature that needs to be deployed on the sandbox to fulfill its integration test too? Most of the time, there are two solutions for the case:
- First, it has to wait for other features to do the test on the sandbox and then they can redeploy another version of the app. No need to mention, that this approach creates overhead for both teams.
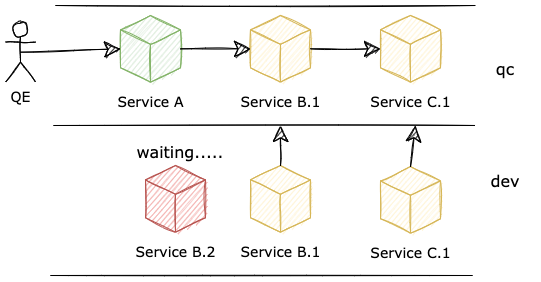
- Second, the team decided to merge two changes into one and deploy it on QC. We can argue that this approach not only provides the testable version for both features but also guarantee compatibility among those two the team is working on. But this is not always the case, because the development should be done independently, and the code in the development phase is so unreliable, (we predict it is and that is why we are catching them by test right?). Now we enable this unreliability to affect both two changes we are making, it slows down both teams on their development. When a bug occurs, the effort to investigate can be doubled cause we have no clue which changes caused it.
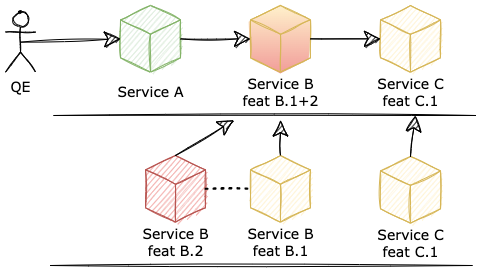
So the first approach is "not easy" cause we have to wait, and time does cost us. The second is too unreliable and also uneasy.
In this case, the dependency among services is direct, what if they are indirect? Team A and C involve in a change, but team B develop some other changes, and our setup for testing will quickly become messy, is it reasonable to request team B delay in delivering their change to keep the testing environment stable for these others? In an ideal scenario, when a service is not involved in a change, it should be running the latest release in the sandbox environment, which does help to simulate the most production-like for the tests.
In this situation, while the constraint that indicates there could be one and only one version of each service deployed on an environment is still remaining, there is no way to do the end-to-end tests for both 2 features independently in parallel.
This statement leads us to an idea: how about in one environment, we enable deploying multi versions of each service, will it solve this irritation in e2e testing? Well, that is probably our approach, however, multi-version deployment is not a magic spell, it introduces some issues that we have to tackle to make it work well.
3. Solution
Let's examine how a multi-version deployment would look like
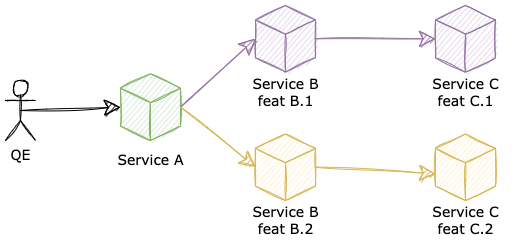
As we can see from the diagram, we enabled 2 versions of the same Service B and Service C to run at a time. In this topology, to test feature 1, a request must start from A, go to B.1, and then finish at C.1. Similarity to testing for feature 2. However, the hard part is how can we control our traffic to go through the exact deployment version that the test is expecting. When a user (in the development team) wants to experience feature 1, how his/her request knows which service to go to after it leaves Service A?
In order to do so, each request itself may need to contain information about the target route, similar to a flight ticket - which not only tells you where is the destination but also which plane will take you there. Request headers are definitely one of the promising places to keep these metadata: they are easy to inject or inspect by many middlewares.
But in particular, how can our infrastructure manage microservice traffic based on these "flight tickets" and how can they be propagated among all services?
3.1. Context propagation
The idea of propagating a context among all components involved is not a new concept. Many could be familiar with the term when working with distributed tracing, which is a widely adopted method for monitoring microservices.
To implement distributed tracing, a service needs to send its requests to its downstream along with some trace identifiers header such as traceid, spanid, b3,... or whatever is defined by the implementing tracers (Jaeger, Zipkin,...). However, these tracers are all based on the opentracing standard, where its specification also defines baggage items: which are the key-value pairs that will be propagated along with the trace. [4]
So now we know that along with headers for tracing, we are capable of passing some key-value pairs which could be defined on our own. This is where we can inject the version dedicated for each request, by defining a format such as: baggage-<service_name>: <release_version>.
If a service is implementing a tracer client such as jaeger, the baggage headers will be transmitted along with other trace metadata without any modification. By leveraging the adoption of opentracing, the routing ticket can now be propagated among services.
3.2. Traffic management
While the request metadata contains routing tickets, how can we dynamically config the route based on these headers?
In a traditional approach, each backend application will be deployed as a number of pods on Kubernetes (which is usually called Deployment), and the access to these pods is defined by Kubernetes Service and Ingress:
- Service is basically a logical set of pods that is defined by some selection policy based on pods labels
- Ingress gives us some more control over traffic by allowing configuration based on path, domain,...
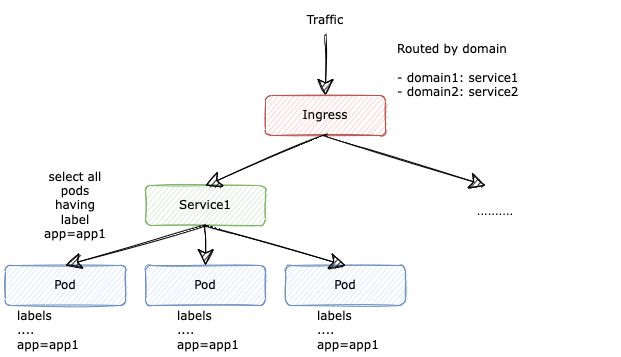
However, header-based routing is not a built-in functionality in Kubernetes Ingress or Service. To achieve this, we may need to install some add-on plugins on our Kubernetes cluster, which could be a service mesh or an ingress controller: Istio, Consul, OpenServiceMesh,...etc the list goes on. But in the end, we chose Istio as our service mesh to implement this function, mostly because of our familiarity with the tool.
A brief about service mesh:
Service Mesh is a modernized service networking layer that provides a transparent and language-independent way to flexibly and easily automate application network functions [5]
In ZaloPay, we have been operating Istio as our service mesh in the production environment. Istio will control the network in our infrastructure by injecting an envoy container as a sidecar proxy in every service pod, which enables its custom network routing policies. A brief description of Istio's architecture is illustrated below:

Istio Architecture (Source)
Then we can use Istio to add up new network abstractions above Kubernetes Service, which are VirtualService and DestinationRule [6]:
- Destination Rule enables Kubernetes Service to be divided into subsets based on selected pods labels. So, when a request is routed to a subset, it will be routed to a single pod based on the load balance rule implemented in that destination rule subset
- VirtualService is a wrapper standing in front of Destination Rule, this is where we implement all the routing rules. We can classify traffic based on request header, URI, etc,...
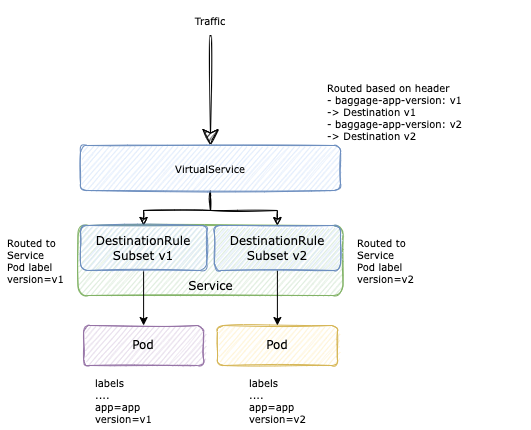
With this setup, traffic can be routed to dedicated pods running a specified version by the clients:
- A backend service will be deployed as a number of deployments, each deployment stands for one version
- All these deployments will be grouped into a Kubernetes Service, so a Kubernetes Service can point to pods running different versions of an app
- Right above, we have the Istio DestinationRule, which divided a Kubernetes Service into many subsets. A Destination contains many subsets, each one for one app version (a Deployment).
- Finally, the routing policy to these Destinations is configured in VirtualService, which will be based on the baggage fields in request headers.
4. Conclusion
By leveraging Service Mesh and Distributed Tracing in our microservice infrastructure, we have enabled the testing environment with multiple versions of the system running in parallel, isolated, and reliable. This solution can speed up our development process to deliver new features to serve business, and also improve our software quality. There would be much more things to tackle on this method to optimize it further and to support more use cases at ZaloPay Platform team. Don't hesitate to join us on this journey.
5. References
[1] https://www.simform.com/blog/microservice-testing-strategies
[2] https://martinfowler.com/articles/practical-test-pyramid.html#End-to-endTests
[3] https://www.nginx.com/blog/introduction-to-microservices
[4] https://github.com/opentracing/specification/blob/master/specification.md#set-a-baggage-item
[6] https://istio.io/latest/docs/concepts/traffic-management

