Tìm hiểu bài toán đồng thuận trong hệ thống phân tán (Phần 3)


1. Mở đầu
Đây là bài blog nằm trong bộ seri tìm hiểu bài toán đồng thuận trong hệ thống phân tán của mình. Ở Phần 1 mình đã giới thiệu tổng quan về bài toán đồng thuận và những vấn đề liên quan xung quanh bài toán. Ở Phần 2 mình trình bày cách mà thuật toán 2PC giúp ta đạt được sự đồng thuận trong hệ thống phân tán. Thuật toán 2PC thật sự còn gặp nhiều nhược điểm, ở bài blog này mình sẽ trình bày về thuật toán Raft để các bạn xem nó đã giải quyết bài toán đồng thuận như thế nào.
2. Thuật toán Raft
Giới thiệu
Thuật toán Raft được thiết kế như thuật toán Paxos về khả năng chịu lỗi và hiệu suất nhưng đơn giản và dễ hiểu hơn. Thuật toán này đã có hơn 40+ open source thực hiện. Hiện nay Raft được xem là tiêu chuẩn để đạt được sự thống nhất trong các hệ thống phân tán hiện đại. Nó được áp dụng cho nhiều dự án lớn như Consul, etcd, InfluxDB, TiDB, CockroachDB, YugaByte DB.
Mình cũng làm demo một Raft-Store đơn giản bằng Golang và etcd, và bên trong mình đã sử dụng thuật toán Raft để đạt được đồng thuận của các node trong hệ thống phân tán của mình.
Các vấn đề chính trong thuật toán
Leader election: node Leader mới cần được bầu trong trường hợp thất bại của một node Leader hiện có. Raft sử dụng bộ định thời gian ngẫu nhiên để bình chọn Leader.
Log replication: node Leader cần giữ log của tất cả các node thông qua bản sao.
Safety: Nếu một trong các node đã cam kết một log entry tại một chỉ mục cụ thể, thì không có node nào khác có thể áp dụng một mục log entry khác cho chỉ mục đó.
Raft basic
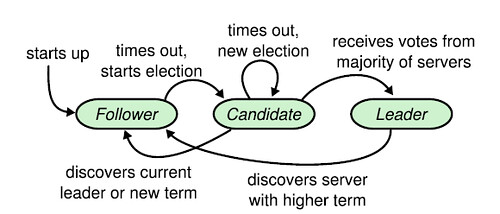
Mỗi node sẽ có 3 trạng thái chính:
Follower: Trong hoạt động bình thường, có một node Leader và tất cả các node khác lànode Follower. Những node Follower bị động vì những node này không đưa ra yêu cầu nào mà chỉ trả lời các yêu cầu từ node Leader và node Candidate.Leader: xử lí yêu cầu của Client gửi lên và gửi đề xuất cho các node Follower.Candidate: là ứng cử viên để bầu chọn làm node Leader mới.
Khi một node được start nó sẽ bắt đầu với trạng thái là Follower.
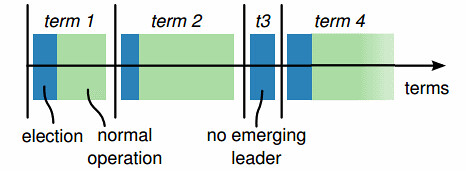
Term là thời gian từ lúc bắt đầu bầu chọn node Leader đến lúc node Leader được bình chọn lại. Thời gian mỗi term có thể khác nhau, mỗi term chỉ có duy nhất một node Leader.
Có 2 loại request:
RequestVotes: node Candidate sử dụng để yêu cầu bình chọn.AppendEntries: node Leader ghi log.
Cách hoạt động của thuật toán Raft như thế nào mời các bạn đọc phần tiếp theo.
3. Cách hoạt động
Leader election
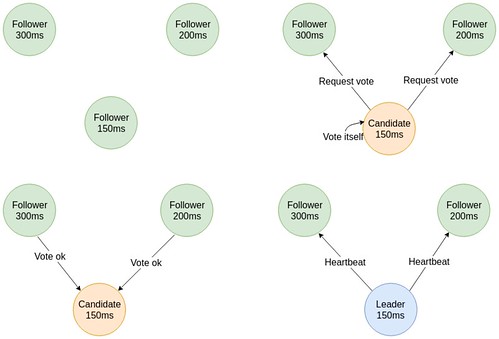
Các node Leader sẽ gửi heartbeat cho tất cả các node Follower theo định kì để duy trì vị trí Leader. Khi node Follower chờ nhận heartbeat bị timeout thì cuộc bầu cử node Leader mới bắt đầu, node Follower sẽ chuyển sang trạng thái Candidate và tăng term lên một đơn vị. Sau khi tự bỏ phiếu cho mình nó sẽ gửi RequestVotes cho tất cả các node trong hệ thống. Có 3 trường hợp xảy ra lúc này:
Node Candidatenhận được bình chọn của đa số các node gửi tới, nó sẽ trở thành node Leader. Và bắt đầu gửi heartbeat cho các node trong hệ thống để duy trì quyền hạn Leader. Các node trong hệ thống sẽ gửi bình chọn cho duy nhất một node candidate trong một term theo kiểu first-come-first-served.- Trong khi chờ đợi phiếu bầu, nếu các node Candidate khác nhận được
AppendEntriestừ một node khác, nó sẽ kiểm tra term. Nếu term lớn hơn term của nó, nó sẽ chấp nhận node đó làm node Leader và trở về trạng thái Follower. Nếu term nhỏ hơn, nó từ chối lệnh AppendEntries và vẫn ở trạng thí Candidate. - Nếu có nhiều node Candidate cùng gửi yêu cầu bình chọn, thì lúc này các node Candidate sẽ không nhận được đa số phiếu bầu, và cuộc bầu cử sẽ kết thúc khi các node Candidate bị timeout. Và cuộc bầu cử mới sẽ bắt đầu.
Có một vấn đề ở giai đoạn này là nếu các node đều khởi động cùng một lúc và có timeout giống nhau thì sẽ không có node nào trở thành node Leader và cuộc bầu cử sẽ bị lặp lại vô tận.
Để giải quyết vấn đề này thì thuật toán Raft sử dụng cơ chế randomized timeout cho các node, timeout giao động từ 150-300ms. Như vậy sẽ luôn có node bị timeout trước và sẽ gửi yêu cầu bình chọn cho các node khác và trở thành node Leader. Đồng thời cũng áp dụng randomized timout cho việc bầu cử Leader mới, khi đó các node Candidate có timeout khác nhau và sẽ hiếm xảy ra trường hợp có hai node Candidate cùng lúc xuất hiện trong một cuộc bầu cử.
Log replication
Mỗi yêu cầu của khách hàng được lưu trữ trong log của node Leader. Log này sau đó sẽ được sao chép sang các node Follower. Thông thường cấu trúc của một entry trong log là:
Term: term hiện tại của nhiệm kì.Index: để xác định vị trí của entry trong log.Command: nội dung metadata.
Quá trình diễn ra như sau:
- Client gửi yêu cầu tới node Leader.
- Node Leader sẽ tạo một entry mới và thêm vào log của nó.
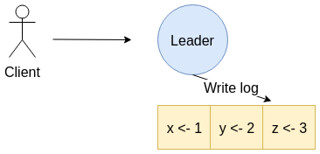
- Node Leader sẽ dùng
AppendEntriesRPC để gửi entry cho tất cả các node Follower. Sau đó node Leader sẽ chờ các node Follower ghi vào log của nó. Nếu ghi thành công các node Follower sẽ thông báo thành công cho node Leader và ngược lại.
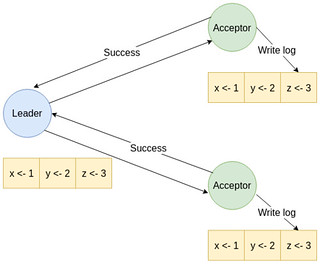
- Nếu node Leader nhận được đa số (quorum) thông báo ghi log thành công thì node Leader sẽ cập nhật state machine của mình với giá trị mới và nó sẽ thông báo cho các node Follower là entry đã được cam kết, và các node Follower nhận được thông báo sẽ cập nhật state machine của mình. Cuối cùng node Leader sẽ gửi kết quả về Client.
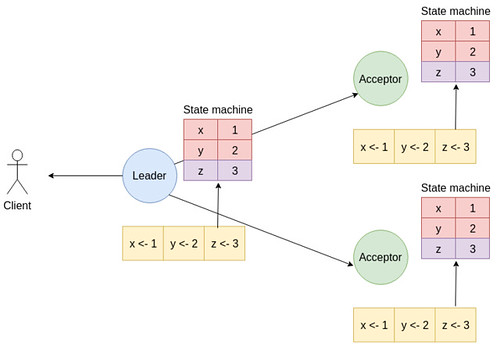
Một số lưu ý ở giai đoạn này là:
- Node Leader sẽ duy trì index cao nhất của log entry đã cam kết và dùng AppendEntries để gửi entry mới cho các node Follower.
- Khi gửi AppendEntries, node Leader sẽ gửi kèm theo term hiện tại và index của log entry trước đó. Nếu node Follower không tìm thấy index log entry nào giống với log entry mà node Leader gửi, nó sẽ từ chối việc ghi log đó có nghĩa là không đồng ý cam kết.
Quorumlà phần lớn thành viên trong hệ thống, nếu hệ thống có n node thì giá trị của biến Quorum(n/2) + 1.
Các vấn đề gặp phải trong giai đoạn này là:
Node Leader bị crashcó thể dẫn đến việc không nhất quán trong log của node Leader và node Follower. Vì node Leader mới chưa hẵn đó có đầy đủ các log.
Giải pháp của Raft:
- Raft buộc các node Follower phải sao chép lại log của node Leader, các log trong node Follower sẽ bị ghi đè.
- Để tối ưu việc sao chép, thì node Leader tìm vị trí index mà nó xung đột với node Follower và node Follower chỉ cần ghi đề log từ vị trí đó trở đi.
- Chú ý là node Leader sẽ không bao giờ ghi đè hoặc xóa log của mình.
Node Follower bị crashthì node Leader sẽ gửi lại cho đến khi thành công.
Safety
Để đảm bảo rằng log được sao chép chính xác và các lệnh được thực hiện theo cùng một thứ tự, vì thế Raft có một số cơ chế an toàn.
The Log Matching Property
Raft duy trì thuộc tính Log Matching Property, nếu hai mục nhật ký riêng biệt có cùng term và index, thì chúng sẽ:
- Nội dung command lưu phải giống nhau
- Các log entry trước đó phải giống nhau.
Election Restriction
Các phần trước mô tả cách Raft bầu các node Leader và sao chép node. Tuy nhiên, các cơ chế được mô tả cho đến nay vẫn chưa đủ để đảm bảo rằng mỗi state machine thực hiện chính xác các lệnh theo cùng một thứ tự.
- Ví dụ: một node Follower có thể không có sẵn trong khi node Leader thực hiện việc ghi log, sau đó node Follower đó có thể được bầu làm node Leader và ghi đè lên log, kết quả là các state machine khác nhau có thể thực thi các chuỗi lệnh khác nhau.
- Raft đã thêm một hạn chế về các node có thể được bầu làm node Leader. Hạn chế đảm bảo rằng node Leader phải
chứa tất cả các logđã cam kết trong trước đó. Trong cuộc bầu cử node Leader, node Candidate gửiRequestVotebao gồm thông tin về log của nó. Nếu các node Follower nhận thấy rằng bản ghi log của nó cập nhật hơn so với log của node Candidate, thì nó sẽ không bỏ phiếu cho nó.
Một số yêu cầu safety khác là:
- Node Leader không bao giờ ghi đè hoặc xóa log của nó.
- Chỉ những entries trong log của node Leader mới được cam kết.
- Các entries phải được cam kết và ghi vào log trước khi áp dụng vào state machine.
- Chỉ có duy nhất một node Leader trong một term.
- Nếu một node đã áp dụng log entry chi state machine thì không có node nào áp dụng một lệnh khác cho state machine của cùng một log entry.
- Khi node Follower bị crash thì tất cả yêu cầu gửi đến node này sẽ được bỏ qua. Khi node được khởi động lại nó sẽ được đồng bộ với log của node Leader.
Còn một vấn đề ghi log khi mà số lượng entry trong log đạt đến ngưỡng cho phép thì ta cần phải có giải pháp compact log hợp lí và lưu lại log xuống đĩa.
4. Ưu điểm, nhược điểm của thuật toán Raft
Ưu điểm
- Quá trình đồng thuận vẫn được hoàn thành mặc dù có một số node bị lỗi. Và có thể hoàn thành khi không cần nhận đủ cam kết từ các node, chỉ cần đa số các node đồng ý cam kết là được.
- Thuật toán dễ hiểu và rõ ràng phần logic.
- Dễ thực hiện và đã có nhiều triển khai mã nguồn mở của Raft có sẵn trên internet. Một số trong đó như Go, C ++, Java.
- Raft sử dụng RPC (các cuộc gọi thủ tục từ xa) để yêu cầu bỏ phiếu
RequestVotesvà yêu cầu đồng bộAppendEntris.
Nhược điểm
- Vì Raft chỉ sử dụng duy nhất một node Leader nên khi có quá nhiều request tới thì hệ thống có thể dẫn đến tắt nghẽn. Trong trường hợp này chúng ta sẽ sử dụng đến MultiRaft.
5. Kết luận
Thuật toán Raft là một thuật toán đồng thuận được thiết kế đặc biệt dễ hiểu. Nó đã giải quyết trọn vẹn bài toán đồng thuận cho hệ thống phân tán có khả năng chịu lỗi. Vì sức mạnh của nó mà đã có nhiều dự án lớn sử dụng nó như Consul, etcd, InfluxDB, TiDB, CockroachDB, YugaByte DB,.... Ở giới hạn bài viết mình không thể trình bày chi tiết hết được nội dung của thuật toán Raft, các bạn có thể tham khảo thêm về thuật toán ở các link mình giới thiệu.