Journey Of Migrating Cloud
After two months of tireless working, all ZaloPay Loyalty's services are in the google cloud. Now I'm here to tell you about our journey to cloud.
At ZaloPay, we have a culture that "being the best at being better". Learning new technology is one of the ways! With that in mind, we decided to move to Cloud, a trending technology. As a member of ZaloPay Loyalty squad, in October 2021, I received a message from my squad leader: our services would be the first to be migrated to Cloud. After two months of tireless working, all ZaloPay Loyalty's services are in the google cloud. Now I'm here to tell you about our journey to cloud.
1) Why do we migrate to Cloud?
So, what is Cloud? There are many definitions of Cloud on the internet. Some say Cloud is just a computer and some say Cloud is a hard drive on the internet. From my viewpoint, I think Cloud definition from AWS (a top Cloud provider) is the most accurate: Cloud is the on-demand delivery of IT resources over the Internet[1]. That means instead of buying, owning, and maintaining physical data centers and servers (on-premise), we can use cloud provider's pre-existing data centers and servers over the internet. The next question is, why migrate to Cloud while the on-premise servers give us full control of our applications?
The answer is: although on-premise servers give us full control of our applications, moving to Cloud also gives us that power and many more benefits:
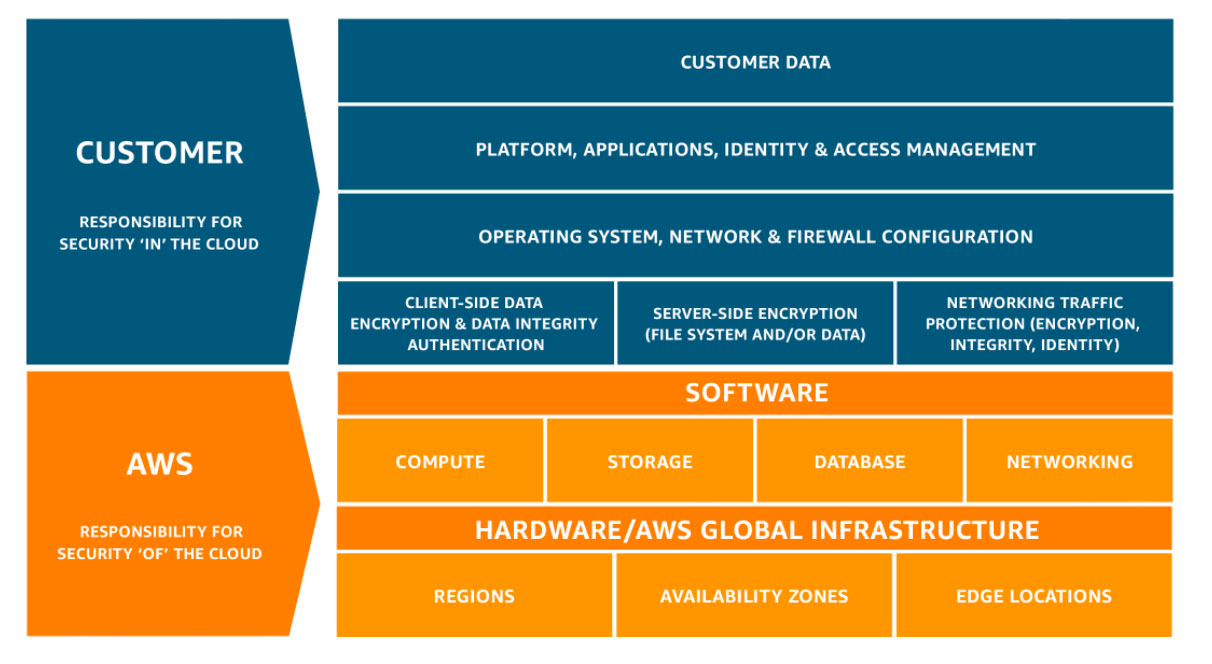
- Full control: most cloud providers follow the Shared responsibility model [2]. This means cloud provider is responsible for Cloud (data centers and the "actual physical servers" servers) while we, the customers, are responsible for what is in Cloud (our applications, data, server's OS...). That means we still have full control of our applications and data
- Achieve high availability: Cloud servers often span multiple data centers all over the globe, so if one is down, we still have backups. Furthermore, most of those data centers are often certificated with Uptime Institute Tiers [3] which means they'll not easily fail
- Better scalability: with the on-premise data center, when we need more servers: we need to buy new servers, plug them into our data center with power and network cables, then configure them from scratch and hope they we'll work as expected. This process often takes weeks or months. With Cloud, new servers will be available in just a few clicks.
- Reduce costs: based on the SRE team calculation, we would save up to 25% cost when hosting everything in Cloud. Furthermore, some cloud services are very cheap, like AWS's EC2 spot instance saves up to 90% cost [4]
- Cloud managed services: or Platform as a Service (PaaS) [5], cloud provider manages the server for us (update underlying OS, backup data...) so that we can focus on developing our products. Most managed services also provide automatic scalability and high availability and pay only when used. Example: GCP memory store, AWS S3, AWS Aurora, ...
Our squad (Loyalty) experienced through 2 migrations: the first migration is from on-premise to GCP, and the second is from GCP to AWS. In this blog, we'll mainly talk about our journey from on-premise to GCP as migration from GCP to AWS is almost the same
The question is why is the Loyalty squad given the honor of being the first squad to migrate to Cloud? The reason is our service is new and ready: Loyalty's services were deployed to K8S 100% and adopted the latest CICD pipeline (at that time). In addition, we always craved to learn new things. Migrating to Cloud would definitely be a big step in our career.
2) Our journey
Enough introduction. Let our journey begin.
Like every journey, we should know what our target is in the first place. We had three main targets:
- Make sure our services work correctly when in Cloud
- Retain integrity of data in our database while migrating
- Minimize downtime: after discussing with the product owner, 2 hours is the maximum downtime
In order to achieve those targets, we divided our migration process into 3 phases:
- Verification: make sure everything works before migration
- Planning: what, how, and when to migrate
- Migration: migrate services and data to Cloud
Phase 1: Verification
The targets of this phase are:
- Verify that performance in Cloud meets our business expectations, in throughput and response time: luckily, most of our services are IO intensive, so with only a small amount of computing resources (8 core of CPU and 16GB ram), we have achieved the expected performance
- Figure out what is the best configurations for servers and services: when migrating to GCP, we used some of its managed services. They are CloudSQL and Memory store, which are simply MySQL and Redis on Cloud. When using them, we only need to provide some configurations like the number of CPU cores, amount of ram, and disk IOPS,... and within a few seconds, we have two databases ready to use. Our task is to find suitable configurations for them to achieve the best performance at the lowest cost. To do that: we first start with high compute resources and load test them to see if it meets our expectations. If it's good, we lower resource configuration. Repeat that process until we find the lowest compute resources that still meet our expectations.
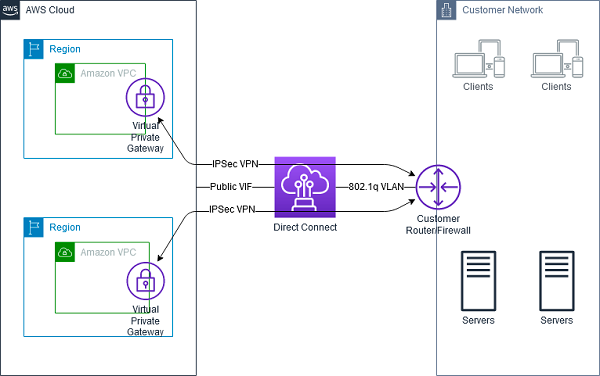
- Make sure that the connection between on-premise and cloud is stable: Loyalty's services are just a small part of ZaloPay system, and they still need to use other internal services in ZaloPay e.g. User Management, Payment Engine, ... which are still on-premises. This is crucial to maintain low latency and stable connections between Cloud and on-premise data centers. Fortunately, Cloud providers like GCP and AWS data centers can directly connect with VNG data center via an ethernet fiber-optic cable [6]. This gives us a low latency and mostly stable connection (sometimes it will be maintained) between 2 data centers. Furthermore, we can also make Cloud servers logically seem like the servers is on-premise data center by using VPN
With those targets in mind, the main task of this phase is to load testing our services in Cloud and configure them until we meet those targets. During the load testing, I discovered much new valuable knowledge:
K8S's request and limit resource configuration are really important
When deploying services to K8s, there are two configurations of computing resources: request and limit resource
Limit resource: the maximum number of resources a pod can use. Pod only uses the amount of CPU within the limit, but when exceeding the memory limit, the pod will be killed
Request resource: the initial resources of a pod are also used to arrange that pod (and others) amongst K8s nodes. For example, a node with 16GB ram can contain approximately 15 pods if the memory request of each pod is 1GB.
This is very important because when:
- Request resource is set too high: waste of unused resources and lead to higher cost
- Request resource is set too low: many pods live on the same node. During peak time, there will not be enough resources to serve user requests.
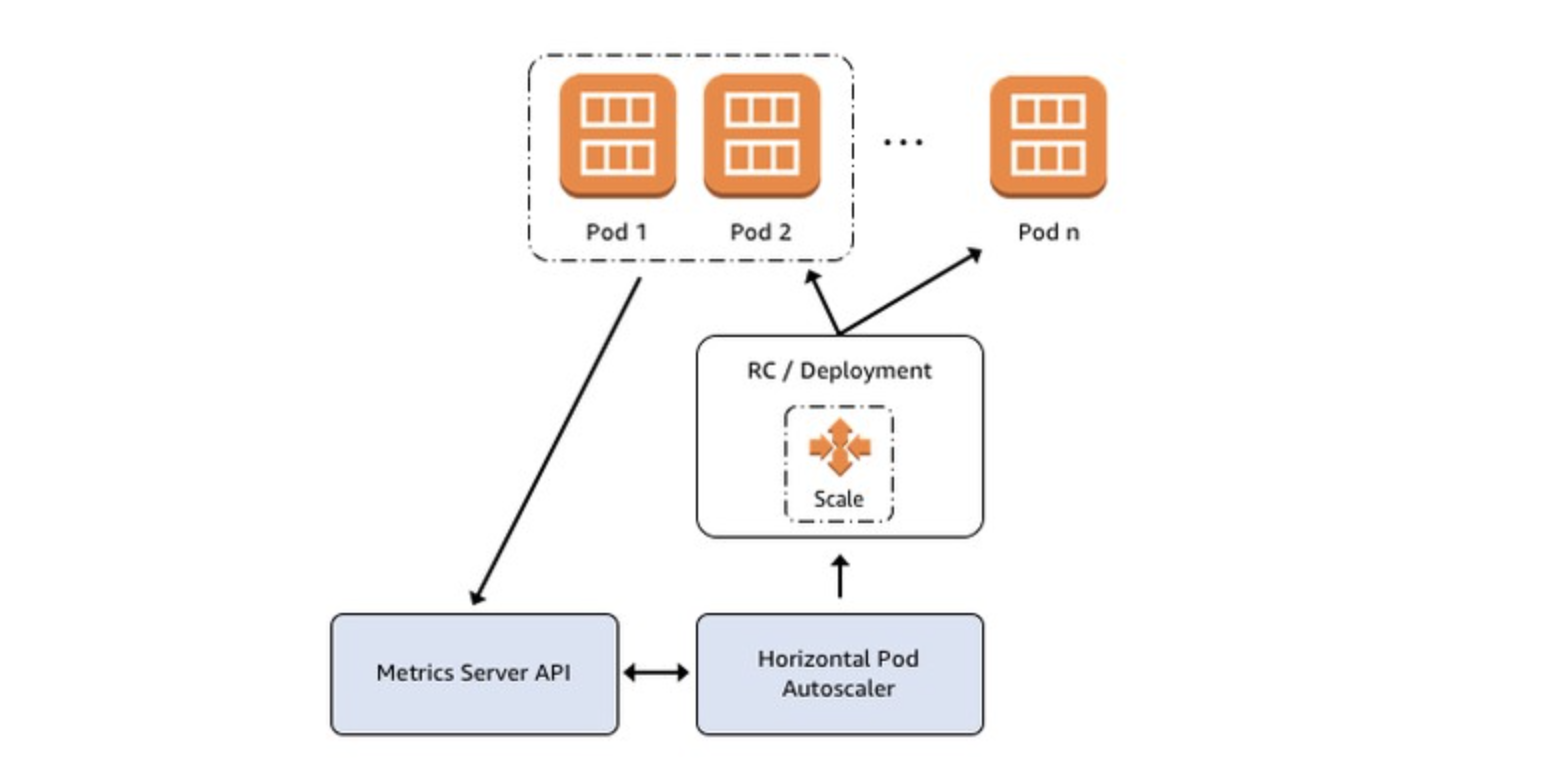
- In order to solve this problem, we should set a limit and request resources to an appropriate amount. Though I think it's hard to get those numbers. The easier way is to use horizontal pod autoscaling (HPA), a built-in feature of K8s. HPA will scale pods based on user-defined metrics like CPU, memory usage, or even the throughput of a pod. During peak times, new pods will be created to adapt. When everything is back to normal, those newly created pods are deleted to save cost
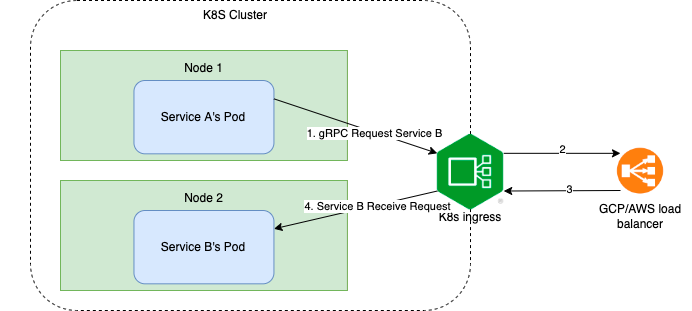
gRPC load balancing in K8s is hard:
Because gRPC is built on HTTP/2, and HTTP/2 is designed to have a single long-lived TCP connection, across which all requests are multiplexed—meaning multiple requests can be active on the same connection at any point in time[7], that means we can not use K8s's service to load balance gRPC requests. We have thought of 2 solutions:
Use an Nginx gateway outside of the K8s cluster. Force all internal requests in K8S using a domain configured in that Nginx, then Nginx route requests back to the K8s cluster. This is a battle-tested solution because we're using this on-premise data center. But it is slower because it adds an extra network hop between 2 endpoints.
Use service mesh like Istio. This has been proven to provide better throughput and lower latency in our load testing
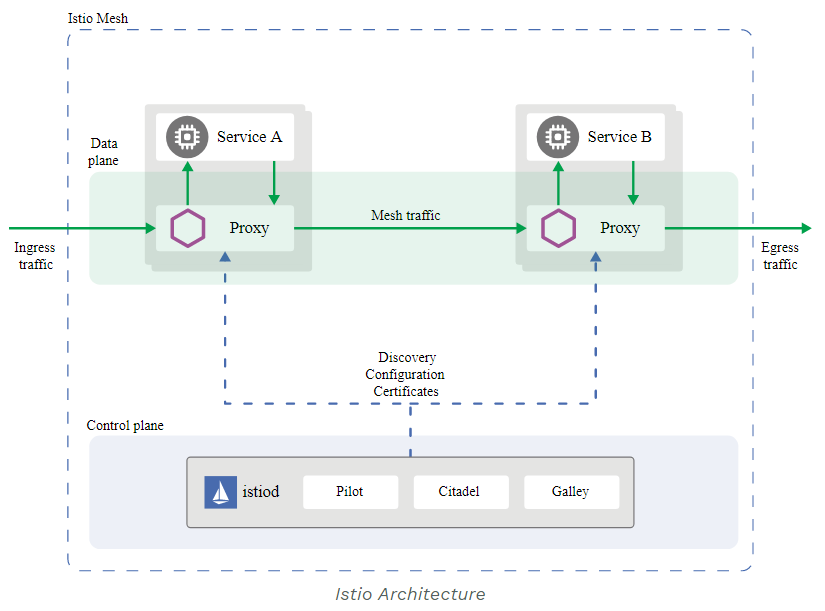
Unfortunately, Istio is not thoroughly tested, and the deadline is near, so we stick with the Nginx solution and will come back to Istio in the future.
Phase 2: Planning
The verification process took about one month. After that, we moved to the phase: planning. This is the time to choose the migration strategy and how to migrate our services with time-boxed downtime (2 hours). About the migration strategy, we want to make minimal changes to Loyalty's services to speed up the migration process and take advantage of Cloud by using some of its managed services.
So, the best migration strategy for us is Replatforming (lift-tinker-and-shift)[8]: we made almost no changes to our services rather than some configurations about backing services. And we adopted some GCP managed services like CloudSQL, Memory store,...
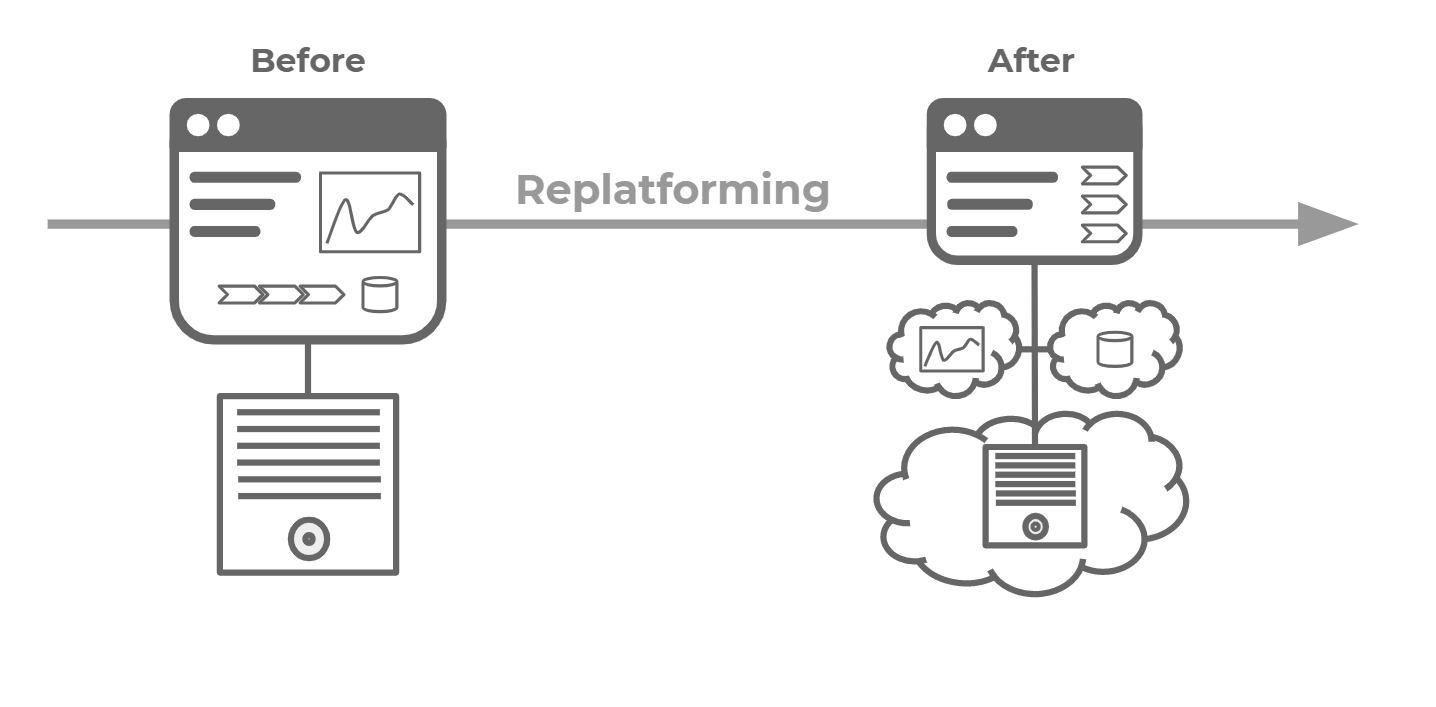
The next task is to define a migration action plan, which must minimize service downtime. For sandbox and staging, everything is easy because it's not affecting real users, but for production, we must be really careful about our plan. After many discussions and meetings, our migration action plan for GCP production would be something like this:
- SRE will set up the infrastructure: K8s cluster, databases, ... and request network necessary ACLs
- Modify our services so that they are in maintenance mode. In maintained mode, there must be no writing to the database
- Start database migration: the most challenging part of the migration
- Deploy service to GCP beforehand with maintained mode turned on
- Entering downtime:
- Switch service's domain to Cloud's gateway: User will see maintain screen when accessing Loyalty's home page
- Stop on-premise services and use Grafana's dashboard and Splunk log to make sure there is no writing to the database
- Verify data integrity
- Turn off maintained mode
Because almost everything is done before downtime, the downtime is very short, only taking about 1 hour and 30 minutes in our estimation.
Phase 3: Migration
The actual migration started here. There are two main parts: services migration and data migration. There is not much to talk about the services migration because it follows the above plan, and we make almost no changes to them. The hardest part is data migration, which causes us many problems.
Like other ZaloPay squads, Loyalty's squad has three databases: sandbox, staging, and production. The three databases only differ in size. While the sandbox and staging database only has 1GB of data. The data size in production at that time is over 500GB. To speed up the migration process, for the sandbox and staging database, we simply used mysqldump to export data and import it to the new database. The story is different with the production database because mysqldump for large data size may take days to export/import and the data is not real-time synchronized. Besides that, GCP also provided us with its database migration service [9], but the sad news is it does not support MariaDB as a source database [10]. Because of that, we had to find another solution. We had thought of 3 solutions:
- Using Debezium or a MySQL instance as a middleman: this's possible but quite complicated to set up. Moreover, our squad members don't have any experience with Debezium, and we don't have enough time to learn.
Using MariaDB on VM: this counters the reason why we use CloudSQL: we want to automate our scaling process. So, we made this the final plan; when everything failed.
- Using GCP's partner migration tools: Cloud providers often come with many partners [11]. One of them is very suitable for our use case is Striim [12]. Unfortunately, this's not free.
Luckily, after discussing this problem with the GCP support team, they kindly issued us a free Striim license. Striim is a database migration tool that is well documented and provides an easy-to-use web interface. The way Striim (and many other database migration tools, as far as I know) works is like this:
- First, We need to get and save the current GTID of the source database; GTID is simply the position of a transaction on MariaDB/MySQL's binlog[13]. Then, It reads all data in the source database tables row by row and inserts those rows into the target database
- Then, based on the GTID saved previously. We configure Striim to read the source database binlog from the GTID so that the data is synchronized in real-time (some database migration tools like AWS DMS do this automatically)
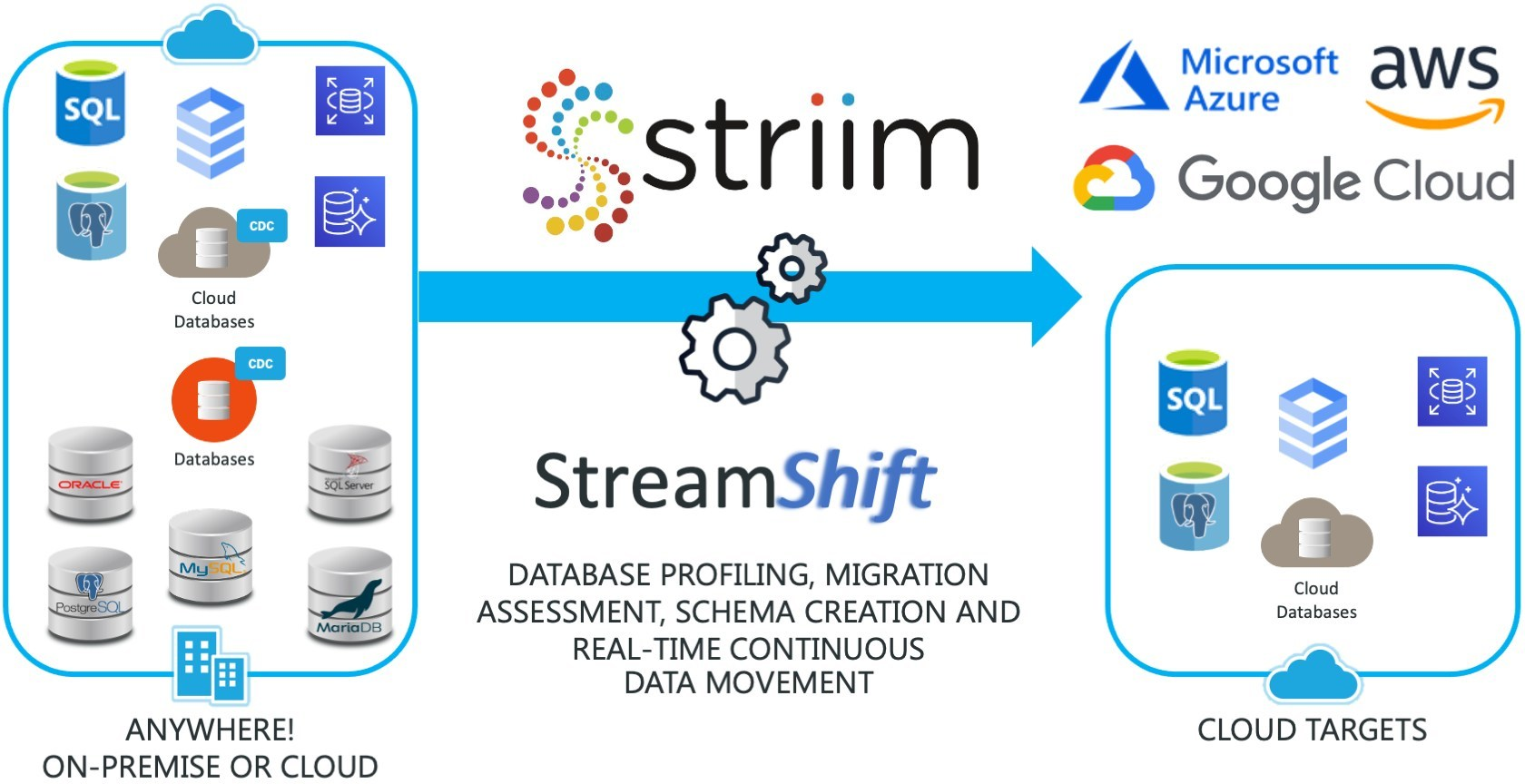
Striim works flawlessly and we can migrate our data to CloudSQL. In less than a day, two databases are synchronized in real-time. The next step is to verify the integrity of data in 2 databases. To solve this, we wrote a small tool in Golang to compare data:
- To ensure data similarity, we use the CHECKSUM TABLE command to get hashed the data in each table and compare them. Unfortunately, the source database is MariaDB, and the target database is MySQL, so the hashed result may be different. And the data size on production is huge (over 500GB), so the CHECKSUM TABLE command will be very slow.
- Another solution is to compare data row by row, which is impossible because we can only afford 2 hours of downtime for the entire migration process (as mentioned).
To comfort the downtime, we divide our database into two categories:
- Critical tables: like user's point storage... we compare the sum of points in each table
- Non-Critical tables: like task log... compare the number of rows is enough.
By using this strategy, database verification only takes about 15-20 minutes.
3) The journey still continues...
Our system has been in Cloud for six months and has been running smoothly most of the time. That was an intense but beautiful journey and we learned many things along the way. Nevertheless, we still have to continuously improve the performance of our services to adapt to new business requirements like applying service mesh, and adopting new Cloud technologies ...
I think the way we migrated our system is still applicable for many other systems and us in the future if there is a need to relocate again 😉. I hope you find this blog interesting and that it will help you with your migration process.
At the end of the day: We are hiring! Please come and join us...
References
[1] https://aws.amazon.com/what-is-cloud-computing/
[3] https://aws.amazon.com/compliance/uptimeinstitute/
[4] https://aws.amazon.com/ec2/spot/?nc1=h_ls
[5] https://docs.aws.amazon.com/whitepapers/latest/aws-overview/types-of-cloud-computing.html
[6] https://docs.aws.amazon.com/directconnect/latest/UserGuide/Welcome.html
[7] https://kubernetes.io/blog/2018/11/07/grpc-load-balancing-on-kubernetes-without-tears/
[8] https://txture.io/en/blog/6-Rs-cloud-migration-strategies
[9] https://cloud.google.com/database-migration
[10] https://cloud.google.com/database-migration/docs/mysql/known-limitations
[11] https://cloud.google.com/partners
[12] https://www.striim.com/integrations/mariadb-mysql/
[13] https://dev.mysql.com/doc/refman/5.6/en/replication-gtids-concepts.html