How we migrated legacy systems to Kubernetes
In this blog, we will tell you our journey while migrating systems to Kubernetes environment
Overview
In the current context, Kubernetes (K8s) and Cloud are developing very fast and becoming popular. Legacy systems deployed on the physical server have many disadvantages in terms of operation, deployment, monitoring, operation cost, etc. Therefore, we need to migrate these systems to the K8s environment to take advantage of its strengths. Everything sounds simple but in fact this change is quite difficult. In this blog, we will tell you about our migration story and lessons.
Approach
In my opinion, we have many ways to do something, but it is important that you see the problem or the hindrance of the thing you are doing. That's right! We have to find the problem and come up with the most suitable migration strategies.
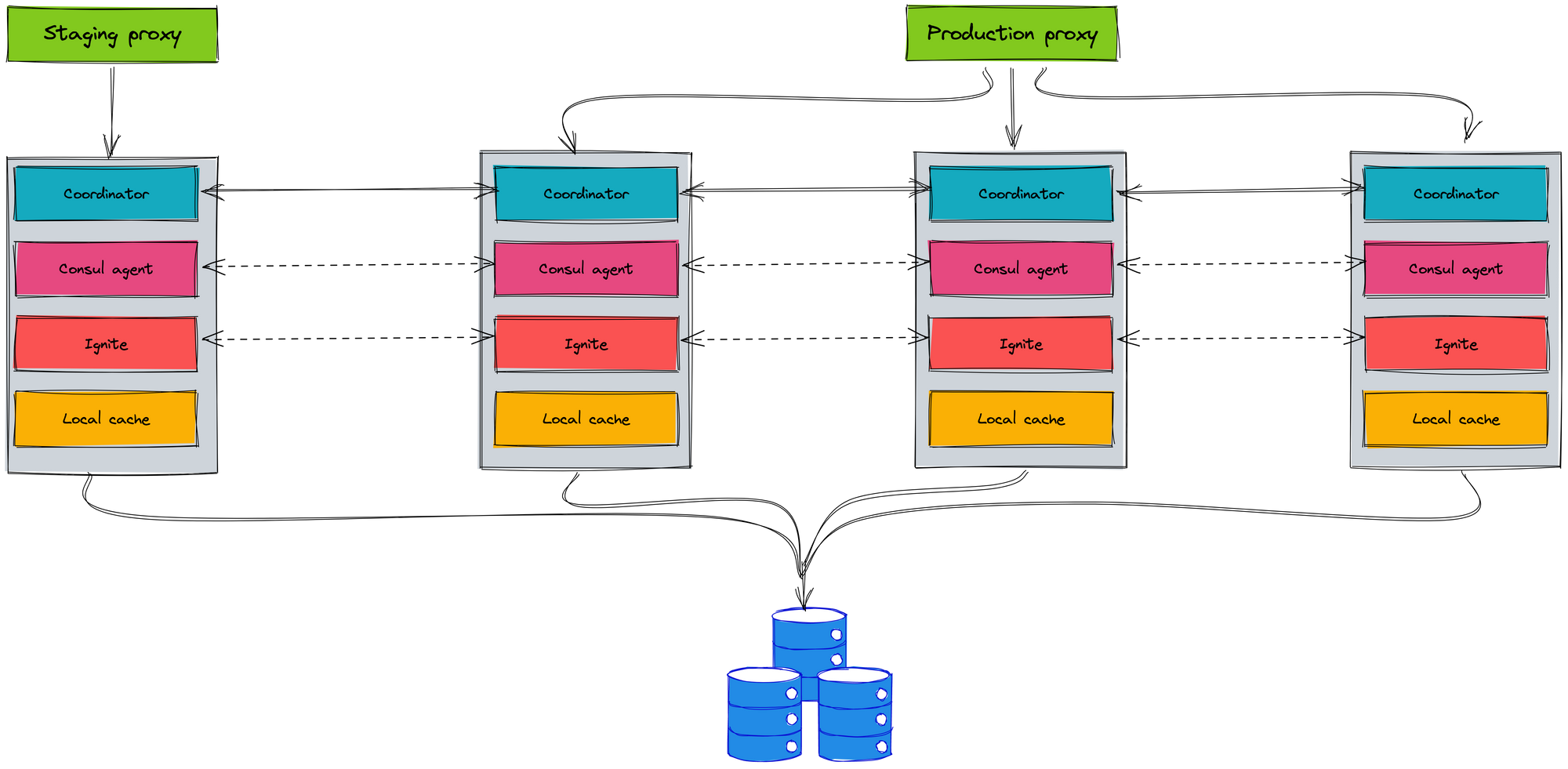
We use the stateful mechanism for our service. We used Ignite which is distributed cache in memory to cache the data. It guarantees performance and easy usage, but it is hard to scale and not K8s friendly. Especially, we had the incident with Ignite when it occurs split-brain. It is the biggest hindrance for us.
We also built the coordinator model between instances by using the Consul to service discovery. A request can be handled by multiple instances. For this reason, it is difficult to deploy in the K8s environment.
On the other hand, we have the luck that our service is the final component of the company's overall system logic. That means our service does not call other services, the service receives the requests, handles requests and returns responses to clients. But it is easy to see that what we just said means that when our service changes, it can have a huge impact on other services. Migrating to K8s environment must be performed carefully to reduce the impact on clients as much as possible.
Before we complete the migration service to K8s, we have the service rollout phase on physical and K8s. It will be difficult when we have multiple deployment environments such as sandbox, staging and production. Each environment has a different deployment model and deployment process. Besides, we must guarantee the quality of service on both physical and K8s, so the testing in the sandbox environment must be easy for a tester.
After clearing our hindrance, we started the discussion to find solutions and strategies for the migration plan.
Choosing strategies for change
Using stateless model
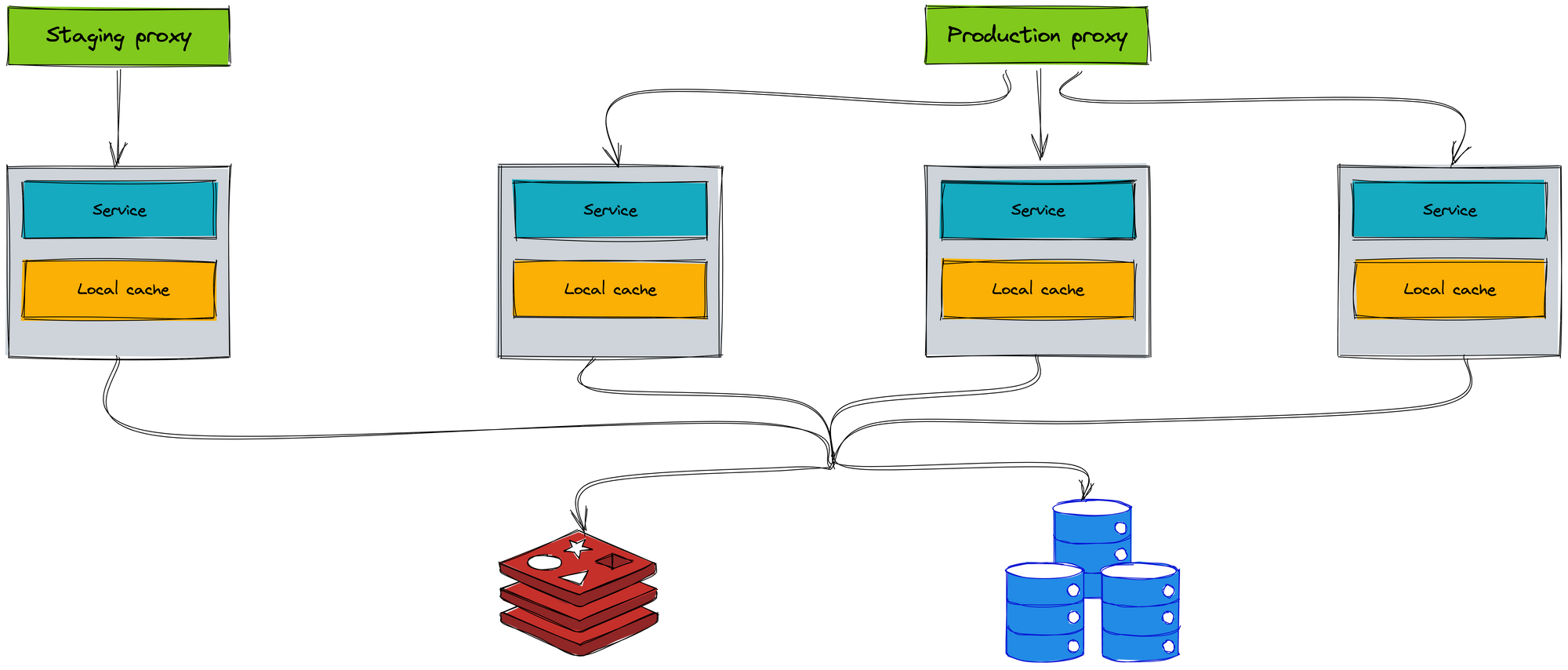
The most important thing is that we hamusthange a stateful model to a stateless model. When you implement the stateless service, you easily scale and deploy on the K8s environment. The Ignite cache is replaced by an external cache. Redis is a perfect choice for the external cache.
The coordinator model does not use between instances. The Consul agent only is used for getting the application configuration. Each instance independently handles the request and does not call other instances.
The local cache only stores the unchanged data. It helps us increase performance when there is no need to query the database.
Everything works well with the new model, so we can deploy our service on the K8s environment. What is the next action? We will switch the traffic of clients to the new deployment on the K8s environment. Of course, it is a simple way, but it is very risky.
This is an important service that has many clients, we have to the migration strategies to reduce the impact on other clients. In the next section, we will analyze the migration problem and how to choose strategies.
Client classification
We separate the client into two types: internal client (offline client) and external client (online client).
- The internal clients are a service that serves users in the company such as admins and accountants.
- The external clients are a service that serves real users on mobile.
Each type of client has a different approach based on its impact on the business. We found that the internal client is low impact, so we test with it first. Therefore, we can deploy our service in two clusters to serve the internal clients and the external clients.
For the external client, we also separate into two types based on traffic:
- A high-traffic client has an average throughput of about 500 request/s.
- A low-traffic client has an average throughput of about 50 request/s.
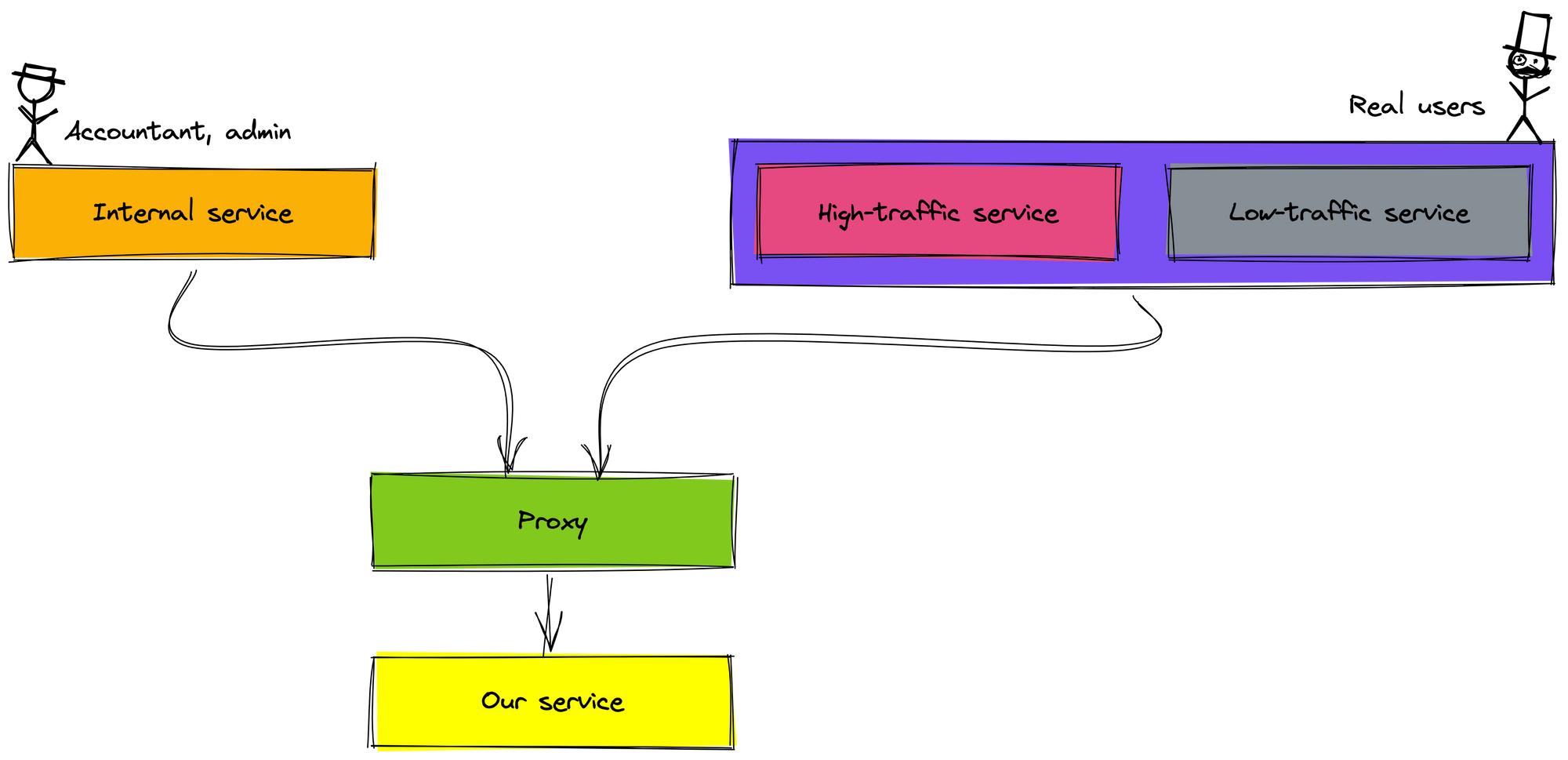
We think that we will roll out the high-traffic client first because we rolled out and tested with the internal client carefully. Moreover, the high-traffic client is one service, the low-traffic client is many different services. If rolling out the low-traffic clients is first, multiple clients must change the configuration.
Environment classification
There are many environments to deploy such as sandbox, staging, and production. They integrate with each other to create a deployment pipeline. For the physical environment, we use the Jenkin to manage the sandbox deployment, then manually sync it to the staging and production. On the K8s environment, we have the CI/CD pipeline to auto manage the deployment. While migration process to the K8s environment, we have to maintain both the above pipeline.
Each environment has different characteristics. For example, the staging environment has a throughput lower than the production environment and it has a low impact on the real user. Or the QE needs to run test cases on the sandbox environment for both the physical cluster and the K8s cluster. Therefore, we choose different migration strategies for these environments.
Next section, we introduce our service the K8s migration journey.
Going to Kubernetes environment
In this section, we talk about staging and production environment, the sandbox environment is presented in the other blog.
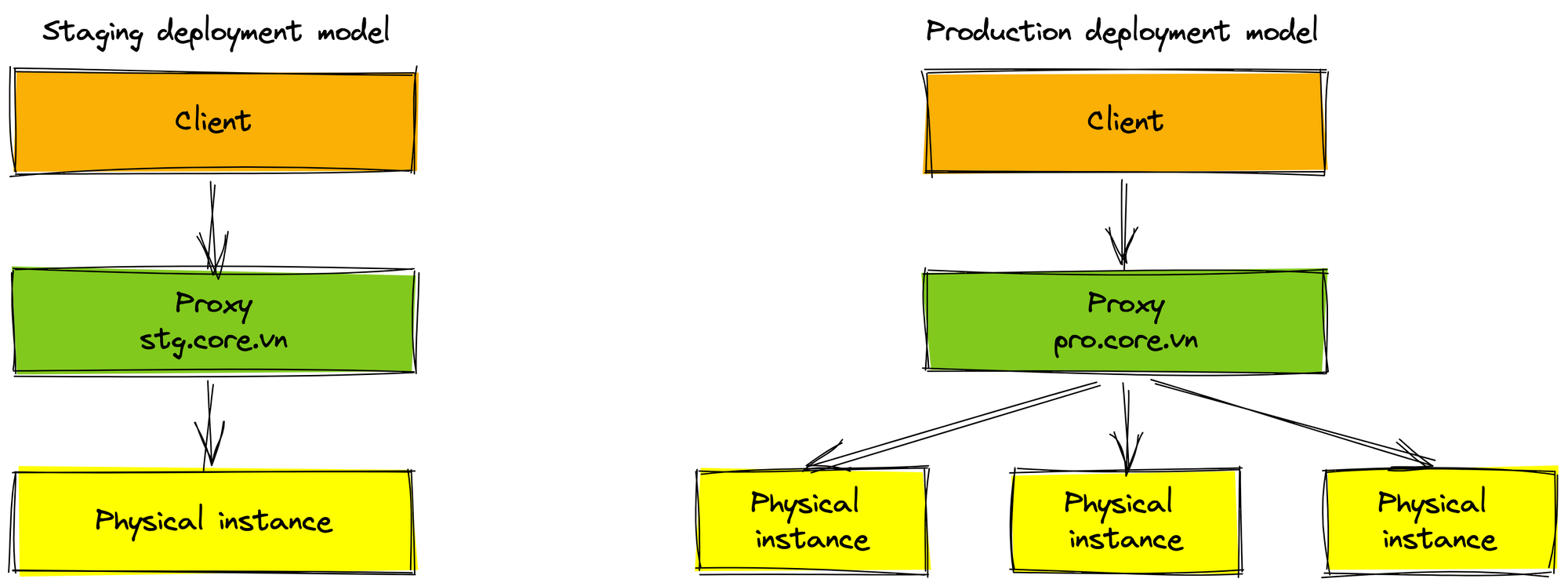
There are more physical instances in the production environment than staging environment. We use proxies to manage the routing traffic to instances. The proxy helps increase the high availability of our service. When any service has occurred problem and shutdown, the proxy forward new requests to other active instances. It also helps us easily migrate our service to K8s environment.
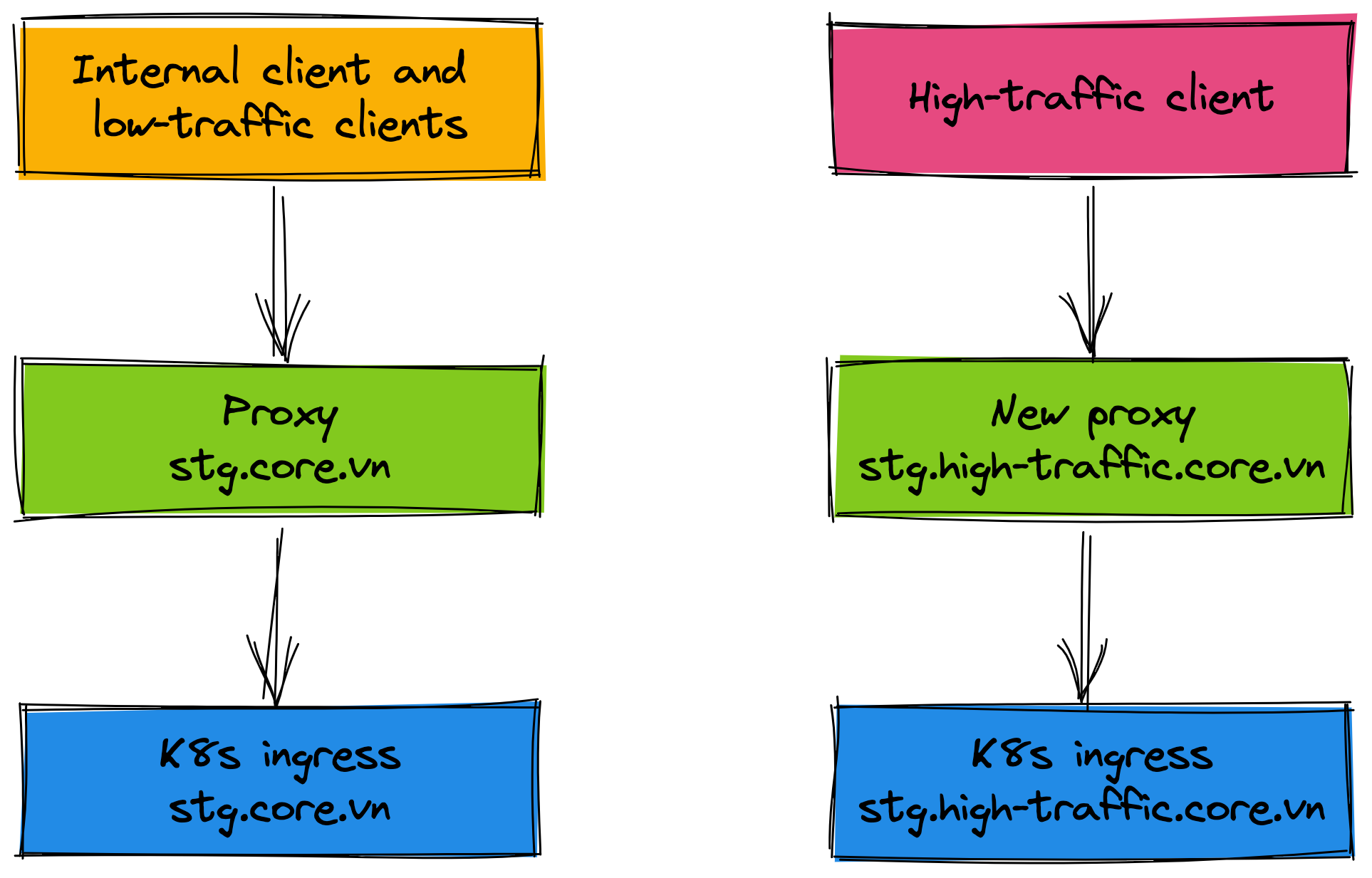
For the staging environment, the internal client and low-traffic clients do not change the endpoint config, they are transparent with the endpoint. The traffic is routed 50% between the physical cluster and the K8s cluster. The new proxy (domain stg.high-traffic.core.vn) is created for the high-traffic client, this proxy only forwards requests to the physical cluster.
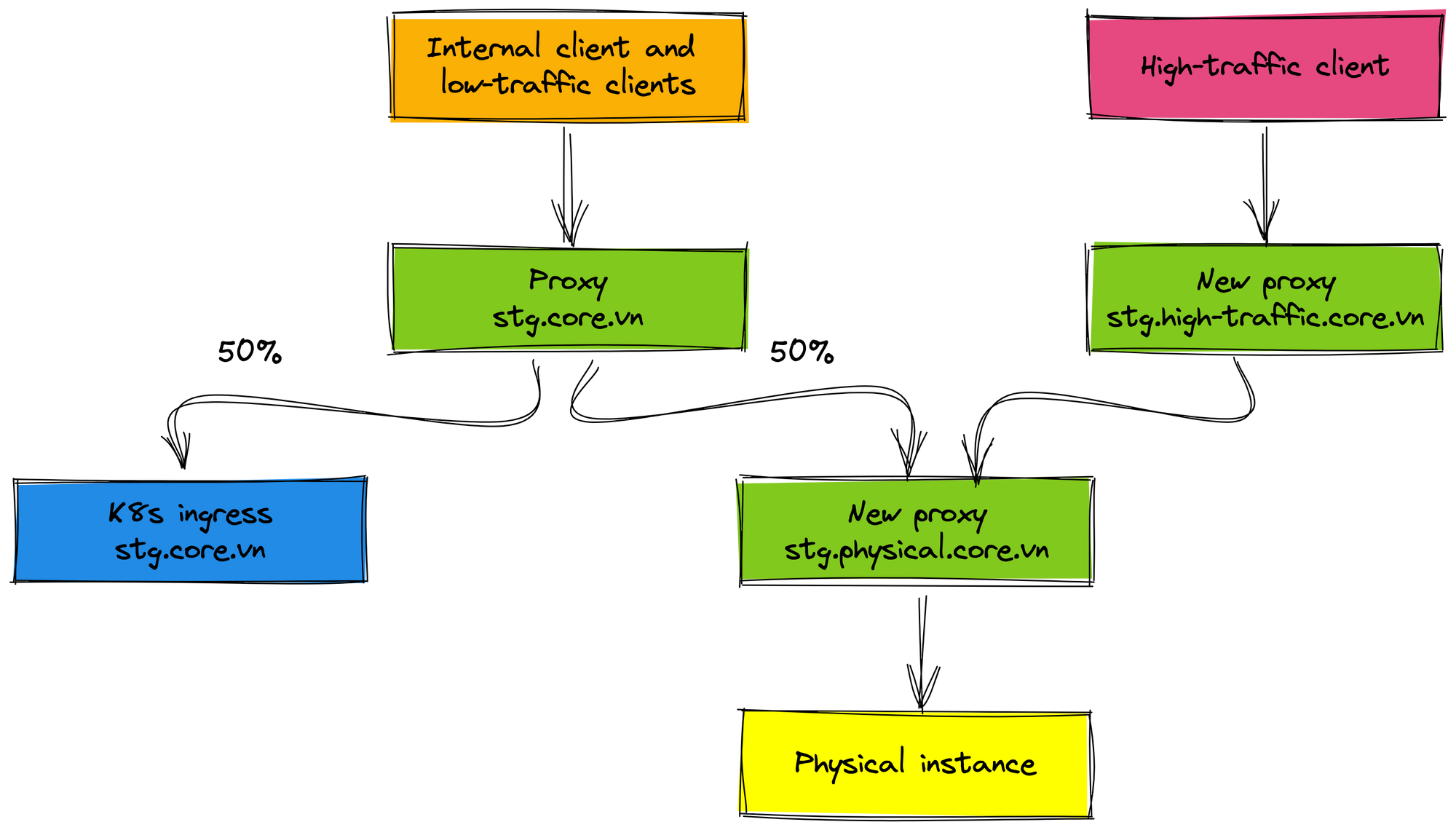
After the internal client and low-traffic clients are stable work and tested carefully, we proceed to roll out 50% traffic of the high-traffic client to the K8s environment. In this case, we add the new proxy for the high-traffic client (domain stg.high-traffic.core.vn) and proxy for the physical cluster (domain stg.physical.core.vn) because we will remove the physical cluster in the future when everything works well on K8s environment. Imagine that you only need to remove the physical proxy when you want to roll out 100% traffic to the K8s environment. It is very easy the rollout process and the clients are not affected.
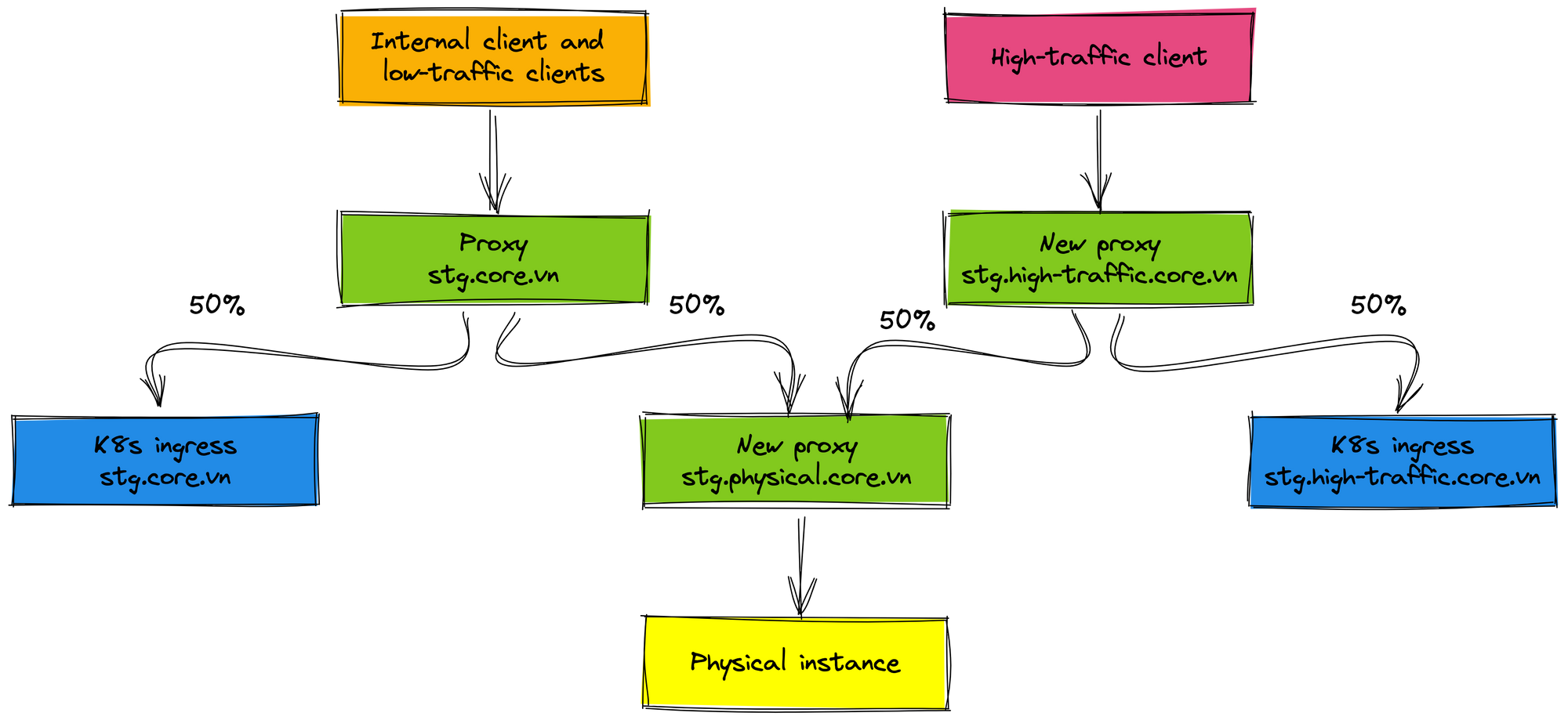
We monitor metrics such as latency, status code... on the staging environment for about 2 weeks. In this range time, the staging service has no issue, we continue to roll out traffic in the production environment.
In fact, there is one concern that is the latency of handling requests on the K8s environment. Our service uses Redis to cache and TiDB to store data, but they are deployed on the physical server. We monitor and see that the latency of calls to the cache and database is increased by about 5 milliseconds compared to when our service was deployed on the physical servers. The SRE team explained to us that from within the K8s cluster, when calling to the outside network, it has to go through more layers such as security layer, proxy, etc.
Now, let's migrate the service to the K8s production environment.
Firstly, the internal client is rolled out to the K8s environment. Some people think that it seems quite risky. Remember it has been carefully tested in the staging environment. Moreover, the internal client has very low traffic, so we can roll back when something becomes problem.
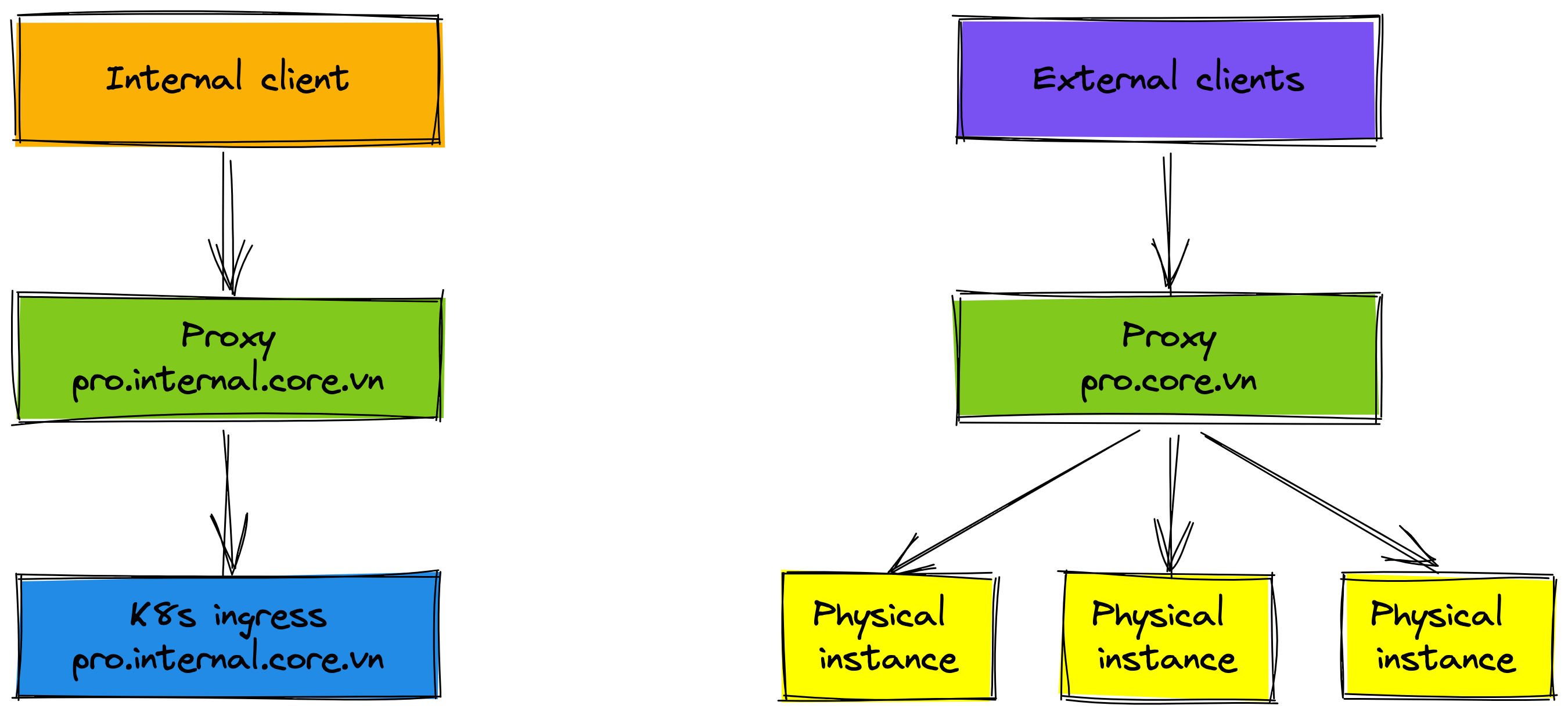
Next, we don't want to affect many clients for changes, we roll out the high-traffic client. That doesn't mean we will roll out 100% traffic to K8s environment right away. The new proxy (domain prod.high-traffic.core.vn) has been created to manage the routing traffic of the high-traffic client. The K8s cluster receives about 10% traffic, 90% traffic is forwarded to the physical cluster. We monitor metrics of service on K8s environment before deciding to roll out more in the future. The traffic percentage to the K8s environment is increased after about 2-3 weeks.
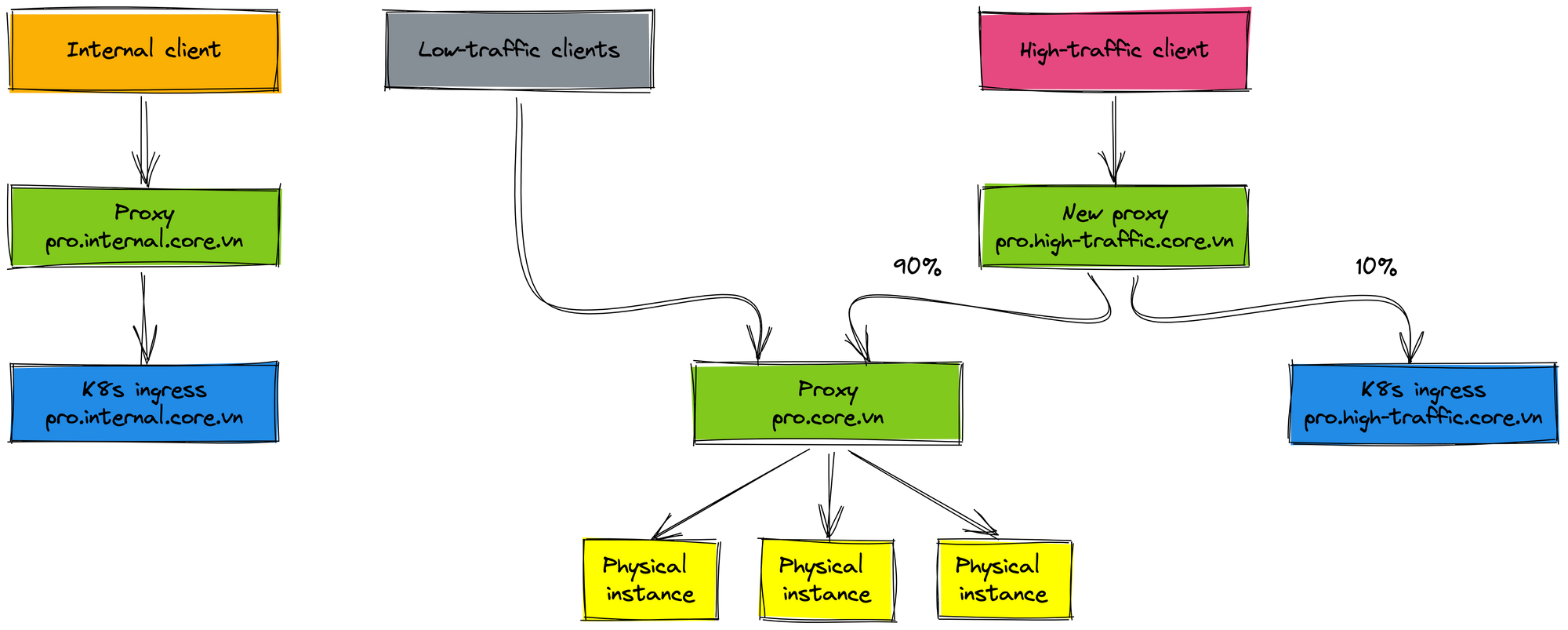
When rolling out 80% traffic to the K8s production environment and everything work well, we decide to roll out 100% traffic of clients to the K8s staging environment. Then, we also roll out 100% traffic of the high-traffic client to the K8s production environment. At this time, you may find that the rollout process is very easy once proxies are set up at previous steps.
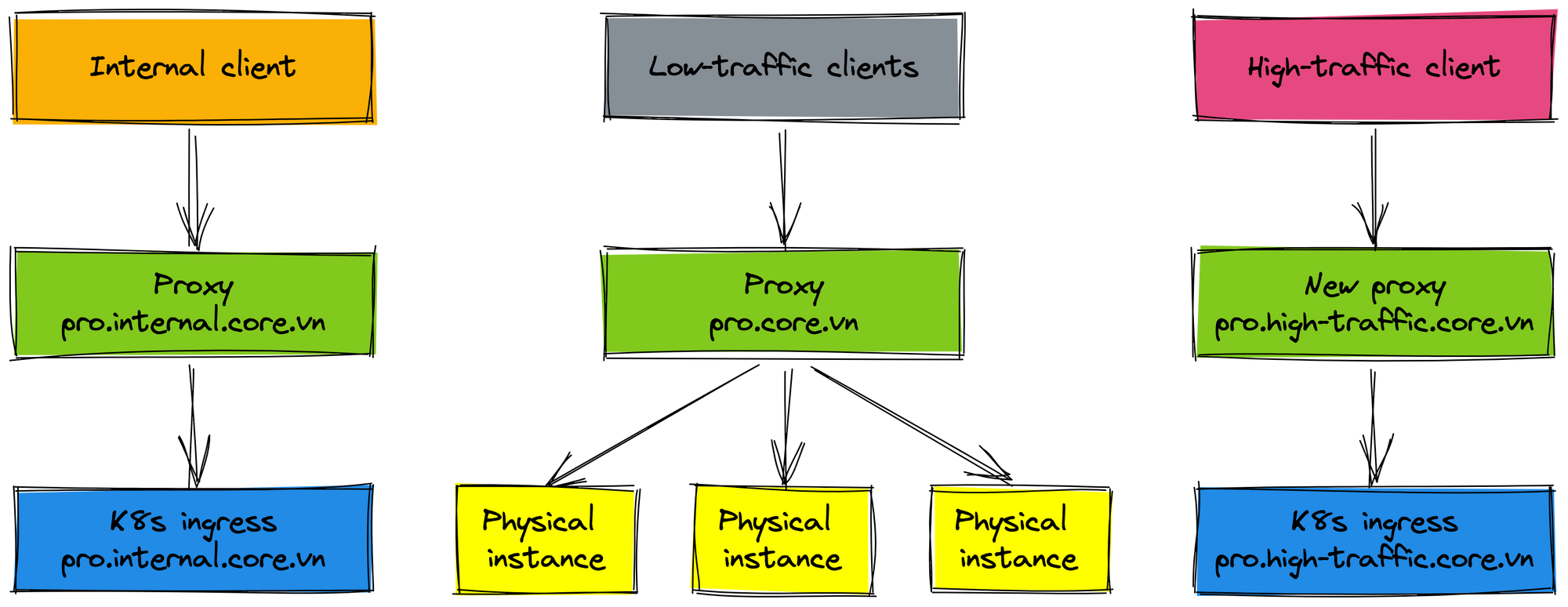
If the physical cluster has not been removed, it will still take us time to maintain two deployments. That means we have to deploy on physical and K8s environments when releasing the new feature. There are low-traffic clients in the production environment not yet rolled out to the K8s environment. If rolling out these clients by changing the endpoint way, these clients have to update their configuration and redeploy. We think that reusing the proxy (domain prod.core.vn) helps these clients not change the configuration. Reusing the proxy also reduces the impact on clients and increases the speed of our rollout process. Let's see the final deployment.
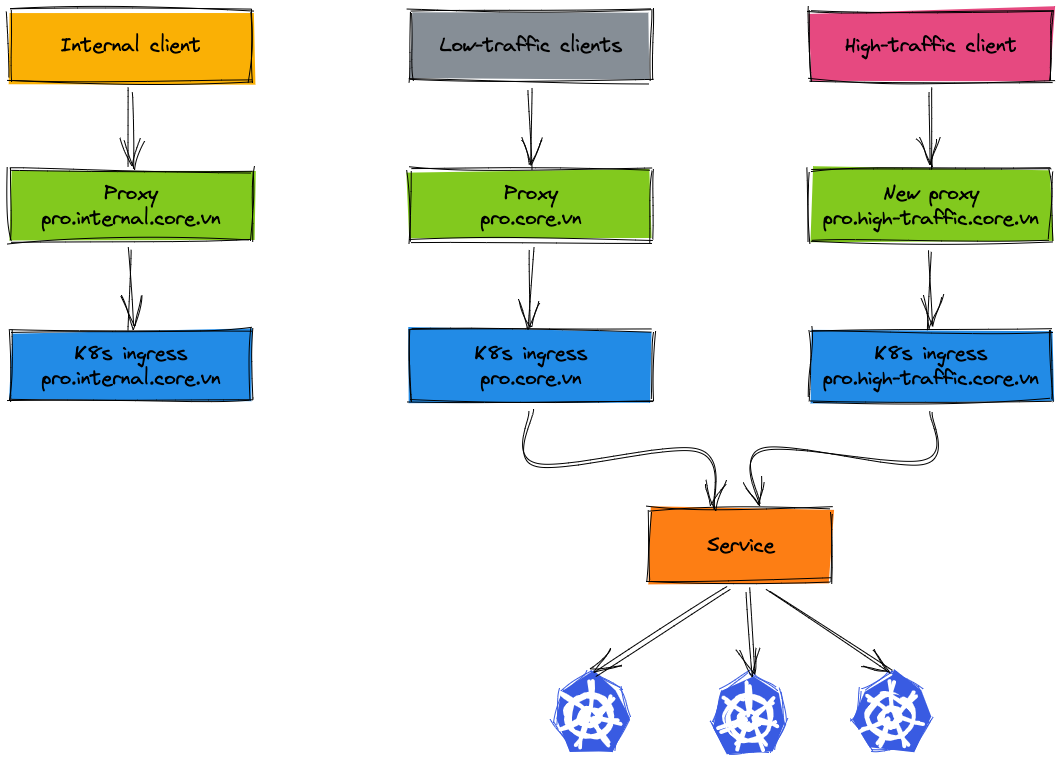
In the migration process, only high-traffic clients and internal clients have to change the endpoint config, the other clients are completely unaffected. For such a complete plan, our team works closely with the system operations team to come up with a design deployment model. But we still have some difficulties in the migration process, the next section will cover these issues.
Difficulties in migration
Migration is an interesting journey but it also has multiple difficulties.
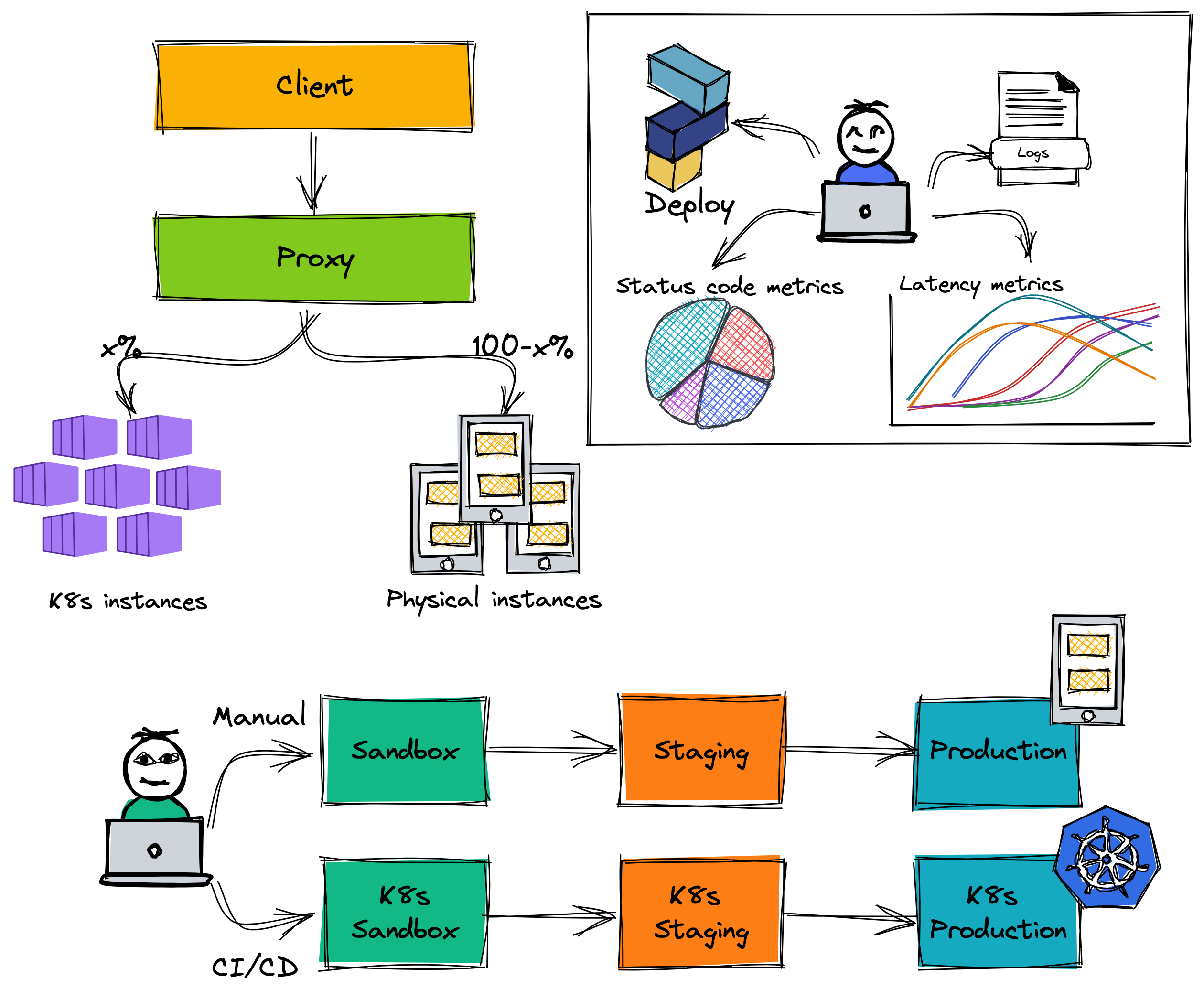
First, maintaining two pipelines for deployment on physical servers and K8s is really laborious. Feature release speed is affected quite clearly and operating costs have nearly doubled. We have to set up metrics on two dashboards to monitor activity service. When checking the log of services, we also have to check on both two environments. Imagine that you have three environments for deployment that are sandbox, staging and production, each environment has two clusters that are K8s cluster and the physical cluster. Operating costs have increased a lot.
Second, our service's latency is increased a bit when looking at the client side because of adding proxies during the migration process. Besides, the K8s environment also has more layers than the physical environment. After the migration is completed successfully, these proxies are removed. The latency also is decreased.
Next, adding proxies to the deployment model has some risks. For example, our company has some rules for networking between servers such as ACL (access control lists). If proxies do not follow these rules, clients cannot send requests to our service. They receive some errors such as permission denied, connection refused, etc.
When rolling out the staging environment, we forgot to open a rule for the proxy which resulted in some requests being blocked. Fortunately, those requests come from our internal admin tool. Before rolling out the client to the K8s environment, we always use this tool to verify network rules.
Finally, the testing in two environments is more difficult. There is no white list for testing our service. In order to test both environments, we need to send multiple requests to the proxy so that it can route to both environments.
Summary
Using the K8s environment instead of the physical environment helps us to improve something such as reducing resource server, operation cost, maintenance cost, increasing release speed, etc. Especially, it's a stepping stone for us to roll out our service to the cloud in the future. Although the migration process has some difficulties and performs for a long time, we learned new lessons and new experiences. Moreover, the plan was successfully completed based on close work between many teams. We are happy to have completed a challenge of the year. Let's welcome the next challenge.